
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Pulumi
- gitops
- eBPF
- Litmus
- blue/green
- tekton
- Kubernetes
- knative
- opensearch
- CANARY
- xdp
- Argo
- Continuous Deployment
- Kubernetes 인증
- Model Serving
- CI/CD
- kubernetes operator
- opentelemetry
- operator
- argocd
- 오퍼레이터
- keda
- Kopf
- seldon core
- mlops
- serving
- nginx ingress
- 카오스 엔지니어링
- MLflow
- Kubeflow
- Today
- Total
Kubernetes 이야기
Ingress 지표를 이용하여 SLO를 충족하기 위한 서비스 수준 지표 (SLI) 본문
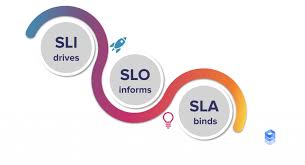
SLO, SLI, SLA란 무엇인가?
- SLO: 서비스 수준 목표
- 내부적으로 대상으로 설정하여 측정 임계값을 구동하는 것(예: 대시보드 및 경고). 일반적으로 SLA보다 엄격해야 한다.
- 예: "99.9%" 가용성
- 키워드: 임계값
- SLI: 서비스 수준 지표
- SLO가 목표에 부합하는지 여부를 확인하기 위해 실제로 측정하는 지표
- 예: 오류 비율, 대기 시간
- 키워드: 측정항목
- SLA: 서비스 수준 계약
- 합의된 내용과 시스템이 SLO를 충족하지 않는 경우 발생하는 상황을 설명하는 법적 계약.
- 예: "99.5%" 가용성
- 키워드: 계약
서비스 수준 관리의 이점
- 손쉬운 설정: 간단한 안내 흐름으로 제공되는 원클릭 설정과 권장 사항 및 사용자 지정을 통해 모든 서비스에 대한 성능 및 안정성 기준을 자동으로 설정.
- 팀 간 안정성 정의: 서비스 경계를 결정하는 데 도움이 되는 SLO 및 SLI 권장 사항을 사용하여 힘든 정렬 프로세스를 방지합니다. 모든 엔터티의 최근 성능 메트릭을 기반으로 안정성 벤치마크를 자동으로 설정.
- 반복 및 개선: Terraform 과 같은 오픈 소스 코드형 인프라 도구를 통한 전체 스택 컨텍스트 및 자동화를 통해 팀은 특정 노드 또는 서비스가 시스템 안정성에 미치는 영향을 파악하고 성능을 신속하게 제어할 수 있다. 서비스 소유자와 비즈니스 리더 모두를 위한 사용자 지정 보기는 운영 효율성을 높이고 더 나은 보고, 경고 및 사고 관리 프로세스로 이어진다.
- 안정성 표준화: 조직 간 팀은 서비스 안정성에 대한 통합되고 투명한 보기를 가지며 고객 대면 SLA를 더 잘 준수할 수 있다. SLO 규정 준수 메트릭 및 오류 예산은 조직이 일관성 있는 방식으로 애플리케이션, 인프라 및 팀 전체에서 안정성에 대해 보고하고 변경 사항을 구현할 수 있는 방법을 제공한다.
이제 nginx ingress를 통한 SLI 지표를 얻는 방법을 알아보자.
nginx 의 설치방법은 다음을 참고한다.
https://kmaster.tistory.com/72
nginx ingress controller 를 helm chart로 배포하기
* 일반 설치 # helm upgrade --install ingress-nginx ingress-nginx --repo https://kubernetes.github.io/ingress-nginx --namespace ingress-nginx --create-namespace * HostNetwork와 DaemonSet을 사용하여 node의 80과 443으로 서비스 하도록 설
kmaster.tistory.com
모든 예시는 ingress_nginx 메트릭을 기반으로 하며 규칙은 Prometheus 규칙을 사용한다.
Prometheus 규칙은 다음을 참고한다.
https://gurumee92.tistory.com/256
기록 규칙(Recording Rule)이란 무엇인가
개요 이번 장에서는 PromQL의 쿼리 성능을 보다 높여줄 수 있는 Recording Rule에 대해 알아볼 것이다. 이 문서에서는 편의성을 위해서 Docker 환경에서 진행할 것이나, 실제 서버 환경에서 어떻게 작업
gurumee92.tistory.com
기본 메트릭 저장을 위한 Rule
Total requests increase
# records the number of requests per hour (increase1h)
- expr: sum by (exported_namespace, exported_service, host, status) (increase(nginx_ingress_controller_requests[1h]))
record: namespace_service_status:ingress_request_total:increase1h
# records the average requests per hour over 30 days, multiplied by 30 days (increase30d)
- expr: avg_over_time(namespace_service:ingress_request_total:increase1h[30d]) * 24 * 30
record: namespace_service:ingress_request_total:increase30dRequest seconds count
- expr: sum by (exported_namespace, exported_service, host) (increase(nginx_ingress_controller_request_duration_seconds_count[1h]))
record: namespace_service:ingress_request_duration_seconds_count:increase1h
- expr: avg_over_time(namespace_service:ingress_request_duration_seconds_count:increase1h[30d]) * 24 * 30
record: namespace_service:ingress_request_duration_seconds_count:increase30dRequest seconds bucket
- expr: sum by (exported_namespace, exported_service, host, le) (increase(nginx_ingress_controller_request_duration_seconds_bucket[1h]))
record: namespace_service_le:ingress_request_duration_seconds_bucket:increase1h
- expr: avg_over_time(namespace_service_le:ingress_request_duration_seconds_bucket:increase1h[30d]) * 24 * 30
record: namespace_service_le:ingress_request_duration_seconds_bucket:increase30d99th Quantile
- expr: |-
histogram_quantile(0.99,
sum by (exported_namespace, exported_service, host, le) (rate(nginx_ingress_controller_request_duration_seconds_bucket{}[5m]))
)
labels:
quantile: "0.99"
record: namespace_service:ingress_request_duration_seconds:histogram_quantile
가용성 규칙으로 통합
Slow requests
# all requests
sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_duration_seconds_count:increase30d)
-
# all fast requests (<=1s)
sum by (exported_namespace, exported_service, host) (namespace_service_le:ingress_request_duration_seconds_bucket:increase30d{le="1"})Error requests
# all requests
sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_total:increase30d)
-
# all successful requests (not 5xx)
sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_total:increase30d{status!~"5.."})Availability
- expr: |-
1 - (
# slow
(
# all requests
sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_duration_seconds_count:increase30d)
-
# all fast requests (<1s)
sum by (exported_namespace, exported_service, host) (namespace_service_le:ingress_request_duration_seconds_bucket:increase30d{le="1"})
)
+
# error
(
# all requests
sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_total:increase30d)
-
# all successful requests (not 5xx)
sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_total:increase30d{status!~"5.."})
)
)
# total
/ sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_total:increase30d)
record: namespace_service:ingress_availability30dError budget
99%의 가용성을 최소로 간주하는 경우에는
100 * (availability30d - 0.99)
최종 rule yaml은 다음과 같다.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: prometheus
role: alert-rules
name: nginx-rule
spec:
groups:
- name: nginx.rules
rules:
- expr: sum by (exported_namespace, exported_service, host, status) (increase(nginx_ingress_controller_requests[1h]))
record: namespace_service_status:ingress_request_total:increase1h
- expr: avg_over_time(namespace_service:ingress_request_total:increase1h[30d]) * 24 * 30
record: namespace_service:ingress_request_total:increase30d
- expr: sum by (exported_namespace, exported_service, host) (increase(nginx_ingress_controller_request_duration_seconds_count[1h]))
record: namespace_service:ingress_request_duration_seconds_count:increase1h
- expr: avg_over_time(namespace_service:ingress_request_duration_seconds_count:increase1h[30d]) * 24 * 30
record: namespace_service:ingress_request_duration_seconds_count:increase30d
- expr: sum by (exported_namespace, exported_service, host, le) (increase(nginx_ingress_controller_request_duration_seconds_bucket[1h]))
record: namespace_service_le:ingress_request_duration_seconds_bucket:increase1h
- expr: avg_over_time(namespace_service_le:ingress_request_duration_seconds_bucket:increase1h[30d]) * 24 * 30
record: namespace_service_le:ingress_request_duration_seconds_bucket:increase30d
- expr: |-
histogram_quantile(0.99,
sum by (exported_namespace, exported_service, host, le) (rate(nginx_ingress_controller_request_duration_seconds_bucket{}[5m]))
)
labels:
quantile: "0.99"
record: namespace_service:ingress_request_duration_seconds:histogram_quantile
- expr: |-
1 - (
# slow
(
# all requests
sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_duration_seconds_count:increase30d)
-
# all fast requests (<1s)
sum by (exported_namespace, exported_service, host) (namespace_service_le:ingress_request_duration_seconds_bucket:increase30d{le="1"})
)
+
# error
(
# all requests
sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_total:increase30d)
-
# all successful requests (not 5xx)
sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_total:increase30d{status!~"5.."})
)
)
# total
/ sum by (exported_namespace, exported_service, host) (namespace_service:ingress_request_total:increase30d)
record: namespace_service:ingress_availability30d
Rule 생성 후에는 다음과 같이 Prometheus에서 생성된 rule을 확인할 수 있다.

https://newrelic.com/topics/what-are-slos-slis-slas
https://docs.bitnami.com/tutorials/implementing-slos-using-prometheus
'Kubernetes > 모니터링' 카테고리의 다른 글
| OpenCost (0) | 2022.11.26 |
|---|---|
| Prometheus를 사용하여 Jenkins 모니터링 (0) | 2022.09.08 |
| Prometheus agent mode (0) | 2022.09.03 |
| Cilium - Hubble UI를 이용한 애플리케이션 시각화 (0) | 2022.05.19 |
| kind + cilium + hubble 구성하기 ( without kube-proxy ) (0) | 2022.05.16 |



