
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 오퍼레이터
- blue/green
- Kubernetes
- Argo
- keda
- Kubeflow
- Litmus
- tekton
- nginx ingress
- Model Serving
- Pulumi
- Kubernetes 인증
- Kopf
- kubernetes operator
- mlops
- argocd
- CI/CD
- 카오스 엔지니어링
- gitops
- serving
- eBPF
- opentelemetry
- seldon core
- Continuous Deployment
- xdp
- knative
- MLflow
- operator
- CANARY
- opensearch
- Today
- Total
Kubernetes 이야기
MLOps 본문

기계 학습(ML) 모델은 크게 모델 개발 및 모델 배포라는 두 가지 주기적인 단계로 구분되어 관리된다. 모델 배포는 일반적으로 대화형 Jupyter 노트북에서 수행되지만 매우 실험적인 단계이므로 프로덕션에 모델을 배치하려면 자동화와 확장성이 필요하다. 이 두 단계 사이를 이동하는 것이 ML 프로젝트가 성공/실패를 가른다.
산업 전반에 걸쳐 DevOps 및 DataOps는 품질을 개선하고 소프트웨어 엔지니어링 및 데이터 엔지니어링 이니셔티브의 시장 출시 시간을 단축하기 위한 방법론으로 널리 채택되었다. MLOps는 ML 시스템을 빠르고 안정적으로 구축, 배포 및 운영하기 위한 일련의 표준화된 프로세스 및 기술 기능이다.
MLOps에서는 파이프라인을 이용해 서로 소통한다. 머신러닝 엔지니어는 데이터를 내려받고, 전처리를 수행하며, 모델을 생성하기까지의 모든 과정을 파이프라인의 형태로 작성하여 소프트웨어 엔지니어에게 전달하고, 소프트웨어 엔지니어는 전달받은 파이프라인에서 생성된 모델을 배포한다.
MLOps 의 이점
- 개발 주기 단축 및 결과적으로 출시 시간 단축
- 팀 간의 협업 개선
- ML 시스템의 안정성, 성능, 확장성 및 보안이 향상
- 간소화된 운영 및 거버넌스 프로세스
- ML 프로젝트의 투자 수익 증가
MLOps 수명 주기 및 프로세스


MLOps 기능
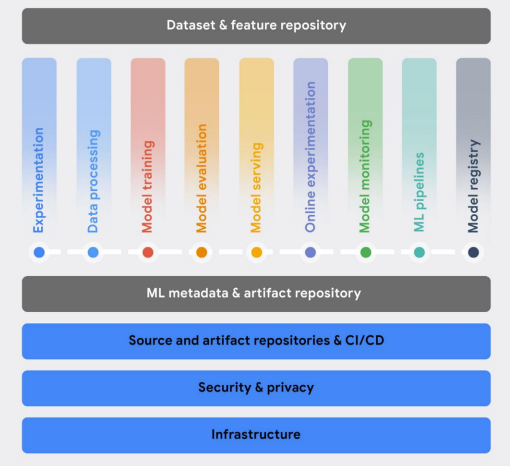
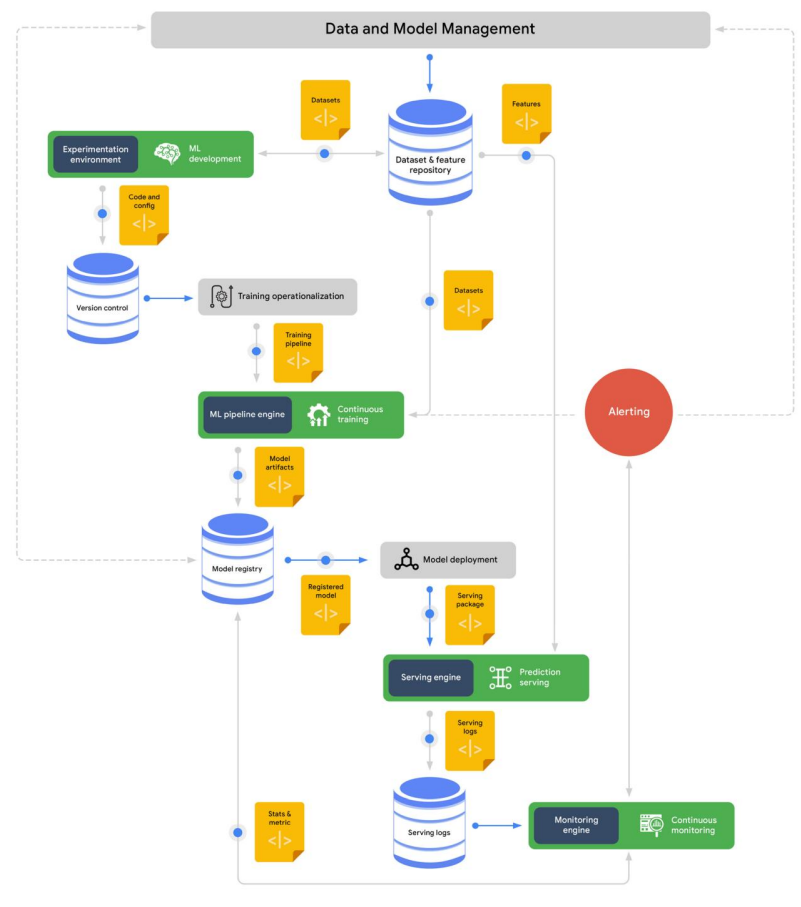
ML 개발

개발 프로세승에서 생성되는 자산은 다음과 같다.
- 실험 및 시각화를 위한 노트북
- 실험의 메타 데이터 및 아티팩트
- 데이터 스키마
- 교육 데이터용 쿼리 스크립트
- 데이터 검증 및 변환을 위한 소스 코드 및 구성
- 모델 생성, 교육 및 평가를 위한 소스 코드 및 구성
- 소스 코드 및 교육 파이프라인 워크플로 구성
- 단위 테스트 및 통합 테스트용 소스 코드
훈련 운영화 프로세스
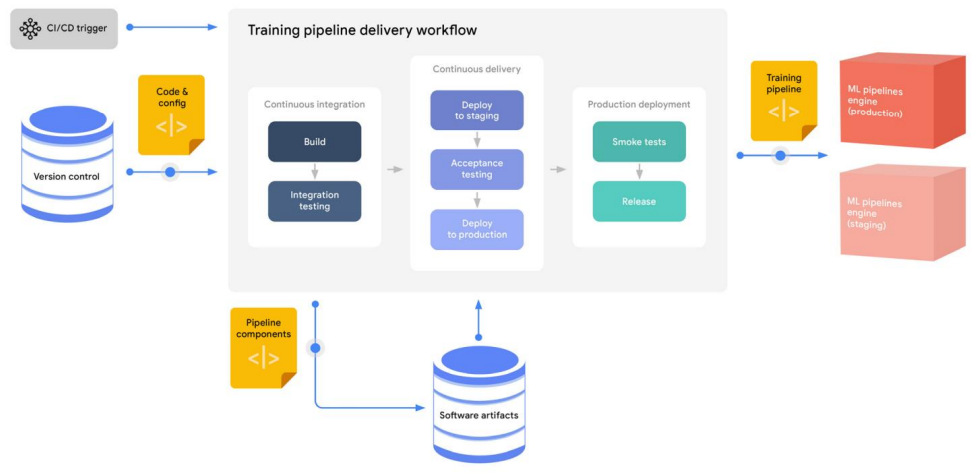
이 프로세스에서 생성되는 일반적인 자산은 다음과 같다.
- 교육 파이프라인 실행 가능 구성 요소(예: 컨테이너 레지스트리에 저장된 컨테이너 이미지)
- 아티팩트 리포지토리에 저장된 구성 요소를 참조하는 교육 파이프라인 런타임 표현
지속적인 훈련
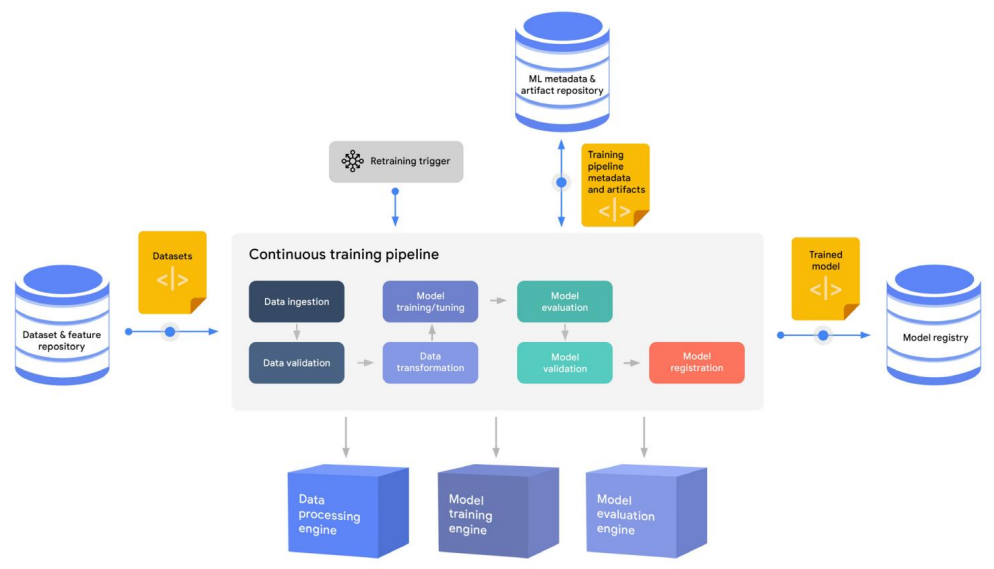
이 프로세스에서 생성되는 일반적인 자산은 다음과 같다.
- 모델 레지스트리에 저장된 훈련되고 검증된 모델
- 파이프라인 실행 매개변수, 데이터 통계, 데이터 유효성 검사 결과, 변환된 데이터 파일, 평가 메트릭, 모델 유효성 검사 결과, 교육 체크포인트 및 로그를 포함하여 ML 메타데이터 및 아티팩트 리포지토리에 저장된 교육 메타데이터 및 아티팩트
모델 배포
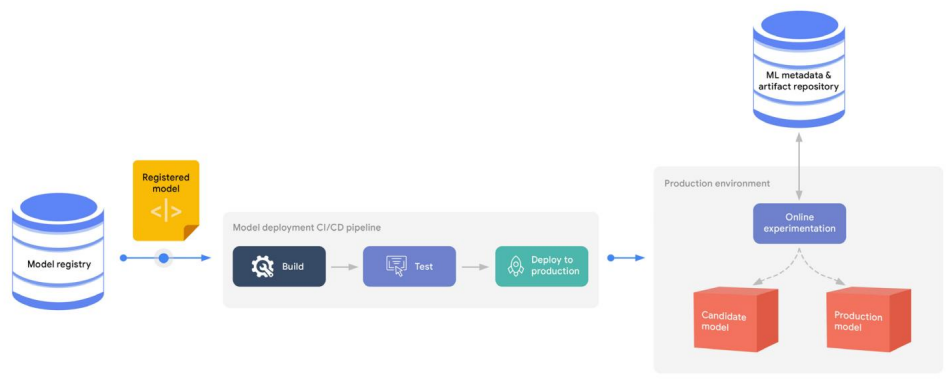
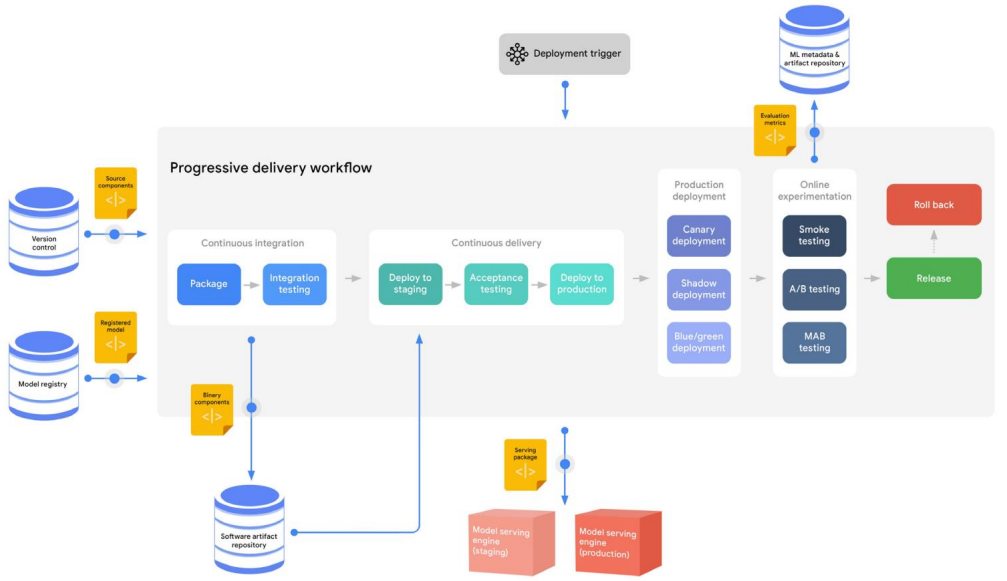
이 프로세스에서 생성되는 일반적인 자산은 다음과 같다.
- 실행 가능한 애플리케이션을 제공하는 모델 (예: 컨테이너 레지스트리에 저장된 컨테이너 이미지 또는 아티팩트 리포지토리에 저장된 Java 패키지)
- ML 메타데이터 및 아티팩트 리포지토리에 저장된 온라인 실험 평가 지표
예측 제공
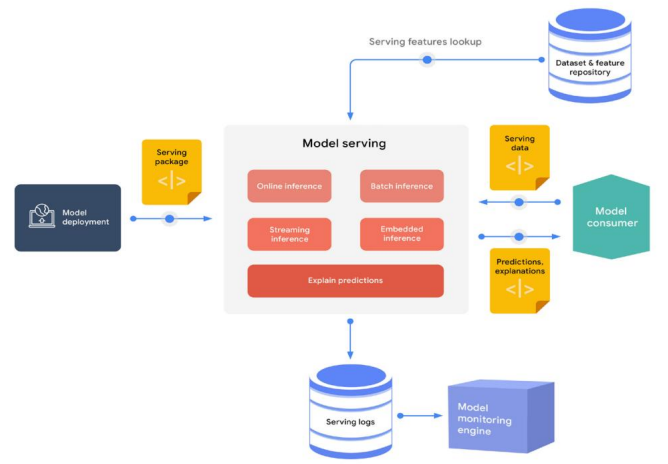
이 프로세스에서 생성되는 일반적인 자산은 다음과 같다.
- 서빙 로그 저장소에 저장된 요청-응답 페이로드
- 예측의 특성 속성
지속적인 모니터링
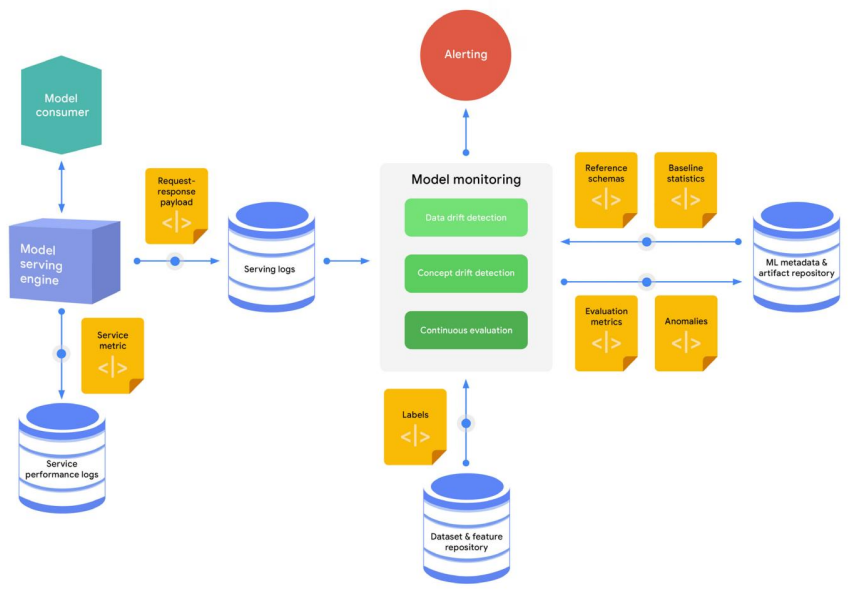
이 프로세스에서 생성되는 일반적인 자산은 다음과 같다.
- 드리프트 감지 중 데이터 제공에서 이상 감지
- 지속적인 평가를 통해 생성된 평가 지표
데이터 세트 및 기능관리
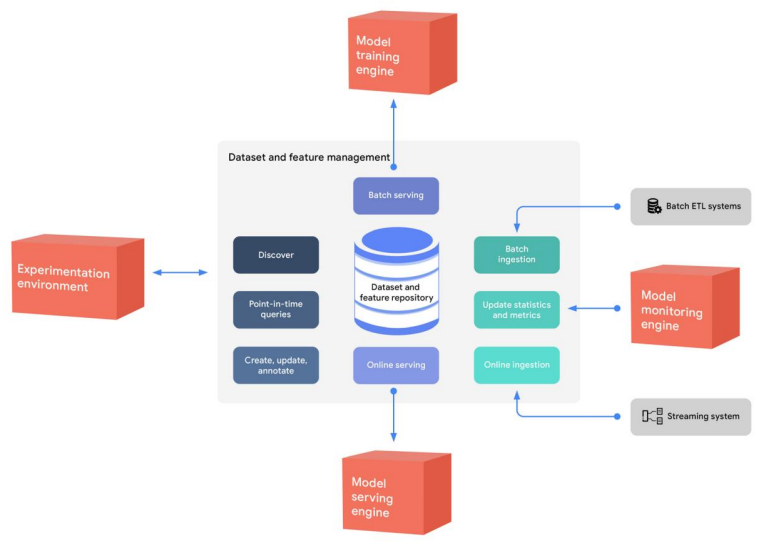
MLOps 전체 프로세스
왜 Kubernetes 인가?
간단하게는 수많은 머신러닝 모델의 학습 요청을 차례대로 실행하는 것, 다른 작업 공간에서도 같은 실행 환경을 보장해야 하는 것, 배포된 서비스에 장애가 생겼을 때 빠르게 대응해야 하는 것 등의 이슈 등을 생각해볼 수 있다. 여기서 컨테이너(Container)와 컨테이너 오케스트레이션 시스템(Container Orchestration System)의 필요성이 등장한다.
컨테이너 오케스트레이션 시스템을 도입한다면, 머신러닝 모델을 개발하고 배포하는 과정에서 다수의 개발자가 소수의 클러스터를 공유하면서 ‘1번 클러스터 사용 중이신가요?’, ‘GPU 사용 중이던 제 프로세스 누가 죽였나요?’, ‘누가 클러스터에 x 패키지 업데이트했나요?’ 와 같은 상황을 방지할 수 있다.
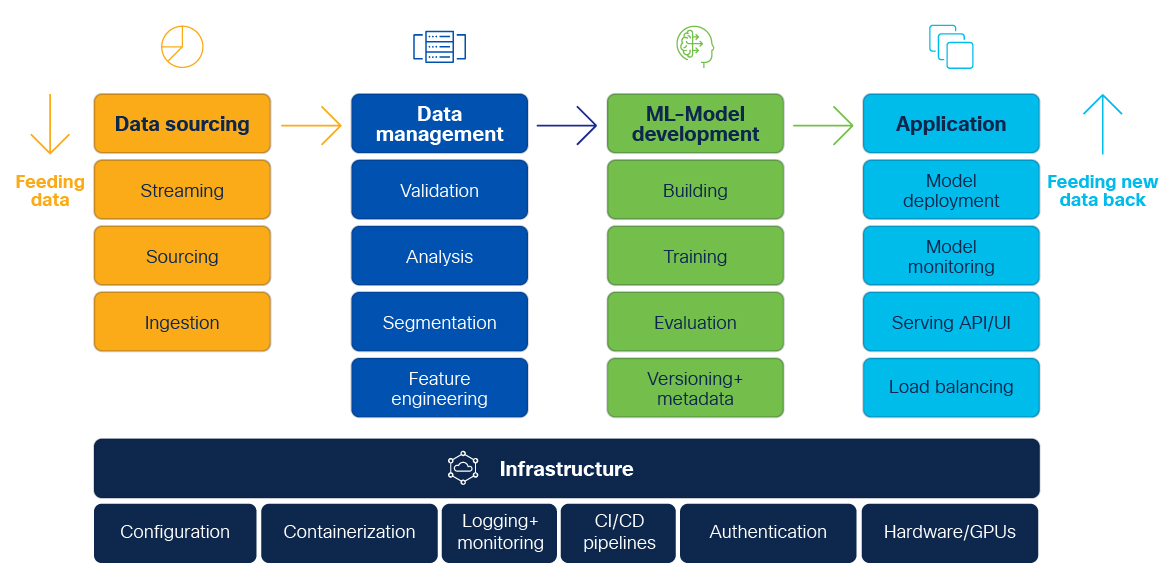
전체 기계 학습 수명 주기에는 기계 학습을 위한 별도의 소프트웨어 구성 요소가 함께 작동할 수 있는 확장 가능하고 효율적이며 안전한 인프라가 필요한데 일반적으로 각 구성 요소에 대한 적절한 구성 관리와 컨테이너화 및 오케스트레이션은 안정적이고 확장 가능한 작업을 실행하기 위해 Kubernetes 를 사용한다.
참고
https://ubuntu.com/blog/mlops-pipeline-with-mlflow-seldon-core-and-kubeflow-pipelines
https://www.iguazio.com/glossary/kubernetes-for-mlops/
https://mlops-for-all.github.io/en/docs/introduction/intro/
https://services.google.com/fh/files/misc/practitioners_guide_to_mlops_whitepaper.pdf
'Kubernetes > MLOps' 카테고리의 다른 글
| Kubeflow - Pipeline (0) | 2023.03.26 |
|---|---|
| MLFlow vs Kubeflow (1) | 2023.03.06 |
| Model Serving (0) | 2023.02.24 |
| Kubeflow - Notebook (0) | 2023.02.24 |
| Kubeflow를 사용한 MLOps (0) | 2023.02.23 |



