
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- opensearch
- 카오스 엔지니어링
- 오퍼레이터
- Pulumi
- Continuous Deployment
- Litmus
- xdp
- argocd
- blue/green
- Kubeflow
- Argo
- eBPF
- MLflow
- knative
- serving
- CANARY
- operator
- tekton
- keda
- Model Serving
- seldon core
- mlops
- Kopf
- Kubernetes 인증
- Kubernetes
- gitops
- opentelemetry
- CI/CD
- nginx ingress
- kubernetes operator
- Today
- Total
Kubernetes 이야기
Ollama and Chainlit으로 Langchain과 RAG 구현하기 본문
최근 유행하고 있는 벡터 저장소와 같은 외부 데이터 아카이브를 사용하여 LLM의 응답 품질을 향상시킬 수 있는 기술인 LangChain 및 RAG를 사용하는 방법을 알아보자.
우선 LangChain 에 대해 알아보자.
LangChain
LangChain은 언어 모델을 기반으로 하는 애플리케이션을 개발하기 위한 프레임워크이다. 이는 다음과 같은 애플리케이션을 가능하게 한다.
- 상황 인식 : 언어 모델을 상황 소스 (즉시 지침, 몇 가지 예시, 응답을 기반으로 하는 콘텐츠 등)에 연결
- 이유 : 언어 모델을 사용하여 추론 (제공된 맥락에 따라 답변하는 방법, 취해야 할 조치 등에 대해)
구성요소

RAG ( Retrieval-Augmented Generation )
RAG는 LLM에게 미리 질문과 관련된 참고자료를 알려준다. 이렇게 하면 보다 정확하게 대답을 생성할 수 있다. ChatPDF 같은 서비스가 대표적인 예이다.
RAG를 사용하면 추론 시 외부 데이터 저장소를 사용하여 보다 풍부한 프롬프트를 생성함으로써 모델의 응답 품질을 향상시킬 수 있다.
RAG에는 다음의 요소가 연관되어 있다.
- Vector Database
- PDF나 HTML 등 데이터
Ollama란
Ollama는 로컬 사용을 위해 오픈 소스 모델을 얻을 수 있도록 지원한다. Ollama는 도커 이미지로 액세스할 수 있으므로 개인화된 모델을 도커 컨테이너로 배포할 수 있다.
설치
curl https://ollama.ai/install.sh | sh
원하는 모델 실행
[root@master ~]# # ollama run mistral
pulling manifest
pulling 8934d96d3f08... 3% ▕███Chainlit
Chainlit은 자체 비즈니스 로직과 데이터를 사용하여 Chat GPT와 같은 애플리케이션을 매우 빠르게 구축할 수 있게 해주는 오픈 소스 Python 패키지이다.
예제
예제는 구조는 다음과 같다.

예제를 만들기전에 우선 jupyterlab을 kubernetes에서 실행 후 아래의 패키지를 설치한다.
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: jupyterlab-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: openebs-hostpath
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: jupyterlab
labels:
name: jupyterlab
spec:
replicas: 1
selector:
matchLabels:
name: jupyterlab
template:
metadata:
labels:
name: jupyterlab
spec:
securityContext:
runAsUser: 0
fsGroup: 0
containers:
- name: jupyterlab
image: jupyter/datascience-notebook:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8888
command:
- /bin/bash
- -c
- |
start.sh jupyter lab --LabApp.token='password' --LabApp.ip='0.0.0.0' --LabApp.allow_root=True
volumeMounts:
- name: jupyterlab-data
mountPath: /home/jovyan
resources:
requests:
memory: 500Mi
cpu: 250m
restartPolicy: Always
volumes:
- name: jupyterlab-data
persistentVolumeClaim:
claimName: jupyterlab-pvc
---
apiVersion: v1
kind: Service
metadata:
name: jupyterlab
labels:
name: jupyterlab
spec:
type: NodePort
ports:
- port: 80
targetPort: 8888
nodePort: 31300
protocol: TCP
name: http
- port: 9000
targetPort: 9000
nodePort: 31301
protocol: TCP
name: http
selector:
name: jupyterlab
pip install chromadb
pip install langchain
pip install BeautifulSoup4
pip install gpt4all
pip install langchainhub
pip install pypdf
pip install chainlit
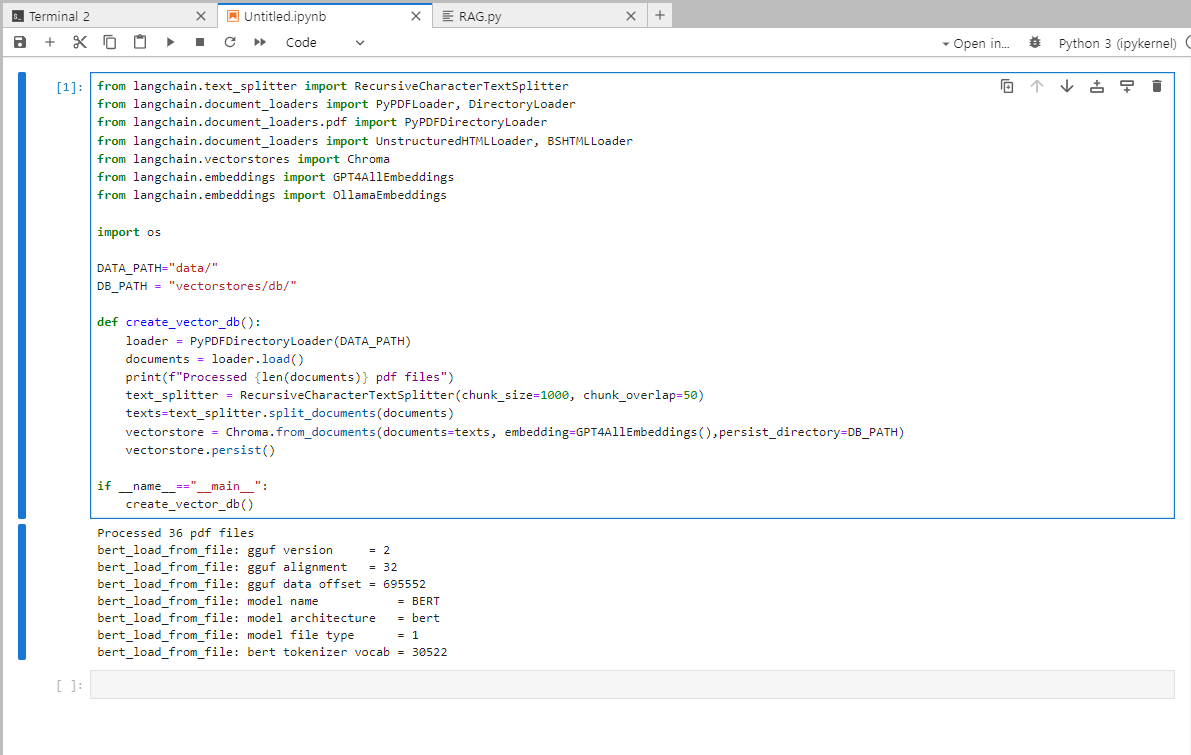
이제 chromadb에 검색에 참조하기 위한 PDF 문서에 대한 전처리를 수행한다. pdf파일은 "https://www.tutorialspoint.com/apache_spark/apache_spark_tutorial.pdf" 으로 하였다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import PyPDFLoader, DirectoryLoader
from langchain.document_loaders.pdf import PyPDFDirectoryLoader
from langchain.document_loaders import UnstructuredHTMLLoader, BSHTMLLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import GPT4AllEmbeddings
from langchain.embeddings import OllamaEmbeddings
import os
DATA_PATH="data/"
DB_PATH = "vectorstores/db/"
def create_vector_db():
loader = PyPDFDirectoryLoader(DATA_PATH)
documents = loader.load()
print(f"Processed {len(documents)} pdf files")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=50)
texts=text_splitter.split_documents(documents)
vectorstore = Chroma.from_documents(documents=texts, embedding=GPT4AllEmbeddings(),persist_directory=DB_PATH)
vectorstore.persist()
if __name__=="__main__":
create_vector_db()
실행 하면 다음과 같이 수행되고, vectorstores폴더에 vector데이터가 저장된다.
이제 chainlit을 사용하여 챗봇을 만들어보자.
#import required dependencies
from langchain import hub
from langchain.embeddings import GPT4AllEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import Ollama
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
import chainlit as cl
from langchain.chains import RetrievalQA,RetrievalQAWithSourcesChain
# Set up RetrievelQA model
QA_CHAIN_PROMPT = hub.pull("rlm/rag-prompt-mistral")
#load the LLM
def load_llm():
llm = Ollama(
model="mistral",
base_url = "http://10.10.0.5:11434",
verbose=True,
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()]),
)
return llm
def retrieval_qa_chain(llm,vectorstore):
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT},
return_source_documents=True,
)
return qa_chain
def qa_bot():
llm=load_llm()
DB_PATH = "vectorstores/db/"
vectorstore = Chroma(persist_directory=DB_PATH, embedding_function=GPT4AllEmbeddings())
qa = retrieval_qa_chain(llm,vectorstore)
return qa
@cl.on_chat_start
async def start():
chain=qa_bot()
msg=cl.Message(content="Firing up the research info bot...")
await msg.send()
msg.content= "Hi, welcome to research info bot. What is your query?"
await msg.update()
cl.user_session.set("chain",chain)
@cl.on_message
async def main(message):
chain=cl.user_session.get("chain")
cb = cl.AsyncLangchainCallbackHandler(
stream_final_answer=True,
answer_prefix_tokens=["FINAL", "ANSWER"]
)
cb.answer_reached=True
# res=await chain.acall(message, callbacks=[cb])
res=await chain.acall(message.content, callbacks=[cb])
print(f"response: {res}")
answer=res["result"]
answer=answer.replace(".",".\n")
sources=res["source_documents"]
if sources:
answer+=f"\nSources: "+str(str(sources))
else:
answer+=f"\nNo Sources found"
await cl.Message(content=answer).send()
여기서 llm을 load시 Ollama를 사용하는데 별다른 설정이 없으면 "127.0.0.1:11434" 로 요청한다. 필자는 Kubernetes환경에 jupyter에 코드를 실행하고, Ollama는 외부 서버에 있어 host정보를 추가하였다.
그리고, ollama 서버도 다음과 같이 host를 지정하여 기동해야 한다.
[root@master ~]# export OLLAMA_HOST=0.0.0.0:11434
[root@master ~]# ollama serve
이제 chainlit 프로그램을 실행해 보자.
chainlit run RAG.py --port 9000 --host 0.0.0.0
2023-12-30 14:02:12 - Your app is available at http://localhost:9000
bert_load_from_file: gguf version = 2
bert_load_from_file: gguf alignment = 32
bert_load_from_file: gguf data offset = 695552
bert_load_from_file: model name = BERT
bert_load_from_file: model architecture = bert
bert_load_from_file: model file type = 1
bert_load_from_file: bert tokenizer vocab = 30522
2023-12-30 14:02:17 - Anonymized telemetry enabled. See https://docs.trychroma.com/telemetry for more information.
실행결과는 다음과 같다. spark shell에 대해 질문한 결과이다.


chainlit 로그는 다음과 같다.

참고
https://python.langchain.com/
https://medium.aiplanet.com/implementing-rag-using-langchain-ollama-and-chainlit-on-windows-using-wsl-92d14472f15d
https://github.com/jmorganca/ollama/blob/main/examples/langchain-python-rag-document/main.py
'Kubernetes > MLOps' 카테고리의 다른 글
| kubernetes에서 nvidia gpu 공유하기 (0) | 2026.03.02 |
|---|---|
| 온라인 서빙과 배치 서빙 (0) | 2024.05.06 |
| Kafka를 사용하여 실시간 데이터 파이프라인 구축 (1) | 2023.12.11 |
| MLflow Serving (0) | 2023.09.09 |
| mlflow (0) | 2023.09.09 |


